最近线上应用出现了一个诡异问题,在访问量无明显增长、线上未做任何变更(代码发布和DB操作)的情况下,某个业务子系统突然出现大量的业务接口超时,MySQL性能急剧下降,系统不可用。
故障现场
当时观察到的主要异常现象包括MySQL出现大量的慢查询、MySQL服务器的system cpu time飙高、MySQL的性能急剧下降、业务接口响应时间飙高、业务系统大量出现获取不到DB connection的异常日志等现象。当时的主要信息如下。
慢查询
慢查询主要集中在这个SQL上。极其简单的一个SQL是不是?读取的数量不到6K
|
|
从慢查询日志中看出这个SQL的执行时间是10s,但是平时这个SQL的执行时间都在0.01ms以内
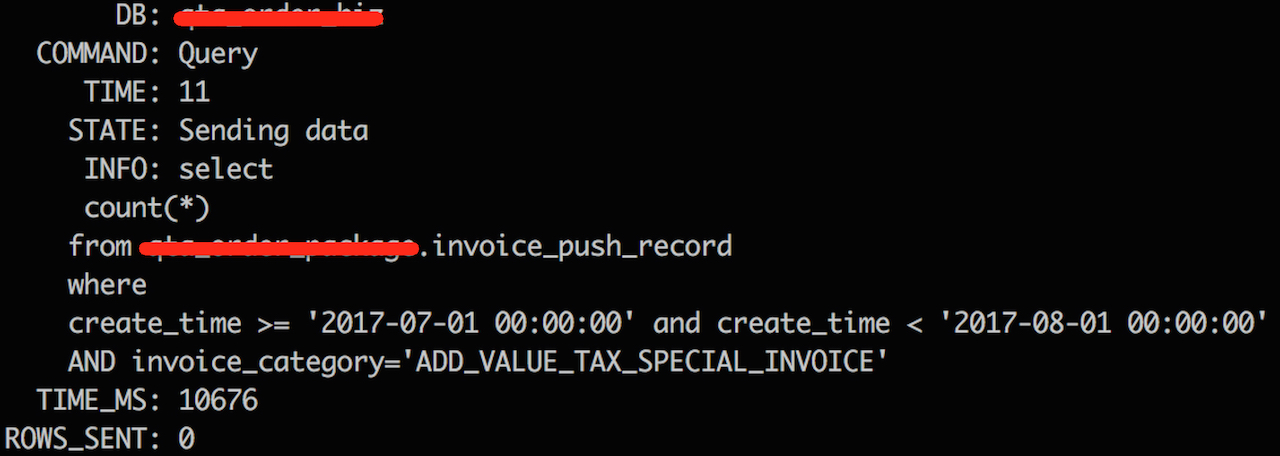
- system cpu time 飙高
MySQL服务器的sy平时不到5%;故障期间飙高到77%,而us和load均未出现波动
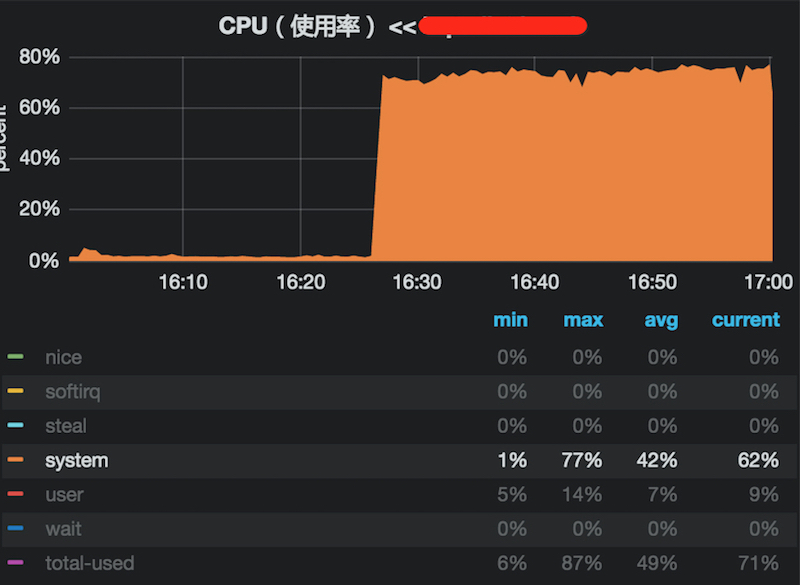
- MySQL的性能急剧下降
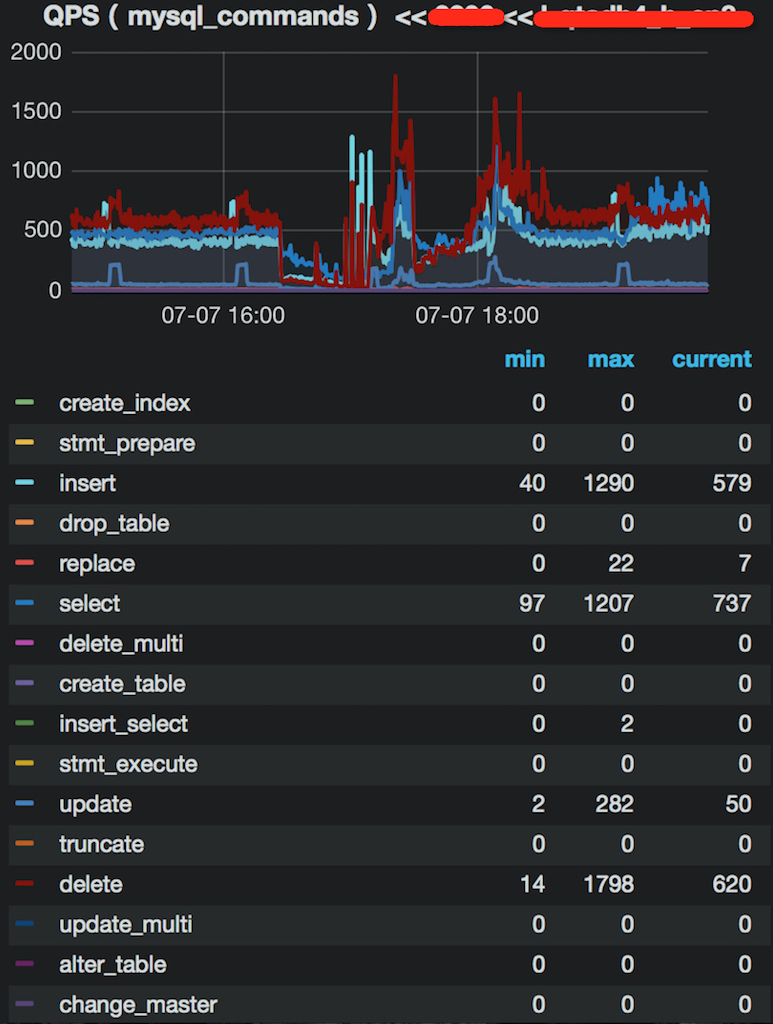
- 业务接口
业务服务接口的QPS在30左右未发生明显变化,但是响应时间从0.01ms飙高到10s

临时解决方案
为了快速恢复故障,将影响降到最低,我们采取了以下两个措施
-
直接kill慢查询
借助pt-kill工具直接干掉慢查询(–match-info “SELECT|select” ),但是由于这个SQL的QPS比较高,即使在不断地kill SQL,但是还不断地出现,DB依旧不可用,故障未恢复。悲催了是不是?
-
服务降级
kill SQL无效,只能下线和这个SQL相关的业务服务接口。将相关的业务服务接口下线后,MySQL服务器的sy逐渐恢复,故障恢复。
故障是否由这条SQL导致呢?这个SQL的嫌疑比较大
故障排查
变更往往是导致故障的主要原因,所以我们先看看故障发生之前,发生过哪些变更。经过确认
线上代码未做过任何变更
MySQL的日常维护未执行过
业务流量未发生明显变化
该SQL在线上已经运行过1年多,不是最近新上线的SQL
网络监控一切正常
因此排除了因变更导致MySQL变慢的情况,由于该业务接口下线后,故障逐渐恢复,所以该SQL存在最大的嫌疑
- slow query分析
该SQL和表都非常简单,这个表的数据量是1W+。平时在线上执行该SQL时,执行时间在0.01ms以下
|
|
|
|
- system cpu time高
第一次遇到这类问题,于是查找了相关资源,发现在数据库内核月报里面提及到:当time_zone设置为SYSTEM时,MySQL访问到的timestamp字段都会作时区转换,在进行时区转换时会竞争全局的mutex,当大量并发访问timestamp时,会引起大量竞争mutex,从而导致sy飙高。
该SQL正好使用到了timestamp,并且线上MySQL的time_zone是SYSTEM,所以很可能是timestamp导致的
|
|
考虑到timestamp在其他的业务场景中也被广泛使用到,但未出现过类似问题,所以当时并不能确定是timestamp导致的
初步结论:尚无定论,有可能是timestamp的time_zone导致,待继续排查
故障重现
为了保证再次出现问题时能及时恢复,我们对这个业务接口做了统一的开关。当再次发布上线时,system cpu time立即飙高,故障重现了,所以可以断定是由timestamp的time_zone导致。
再次上线时,观察到system cpu time飙高,和故障现象一致
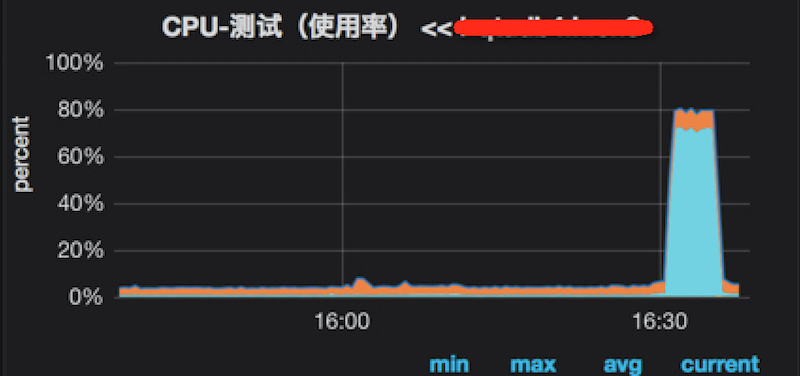
为什么在定位到具体原因之前就发布上线呢?因为经过评估即使再次出现问题能通过开关来立即恢复,可控;另外,对于业务而言,即使这期间短暂出现问题在业务接受范围之内,可接受。
原因定位
到底是不是time_zone导致,压测一下便知。在线下借助sysbench对该SQL进行压测(num-threads=30),该问题立即复现。
- sysbench
压测时,sys cpu time飙高,sys飙高到78%
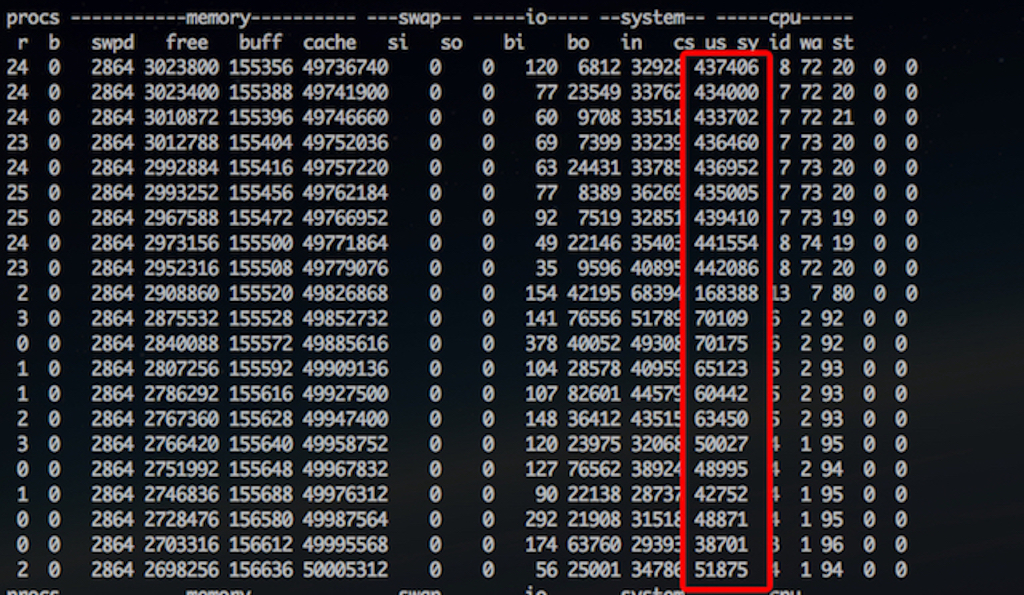
- vmstat
上下文切换的次数变化并不大,涨了10倍,但运行队列r变化比较大,因为是并发压测引起的
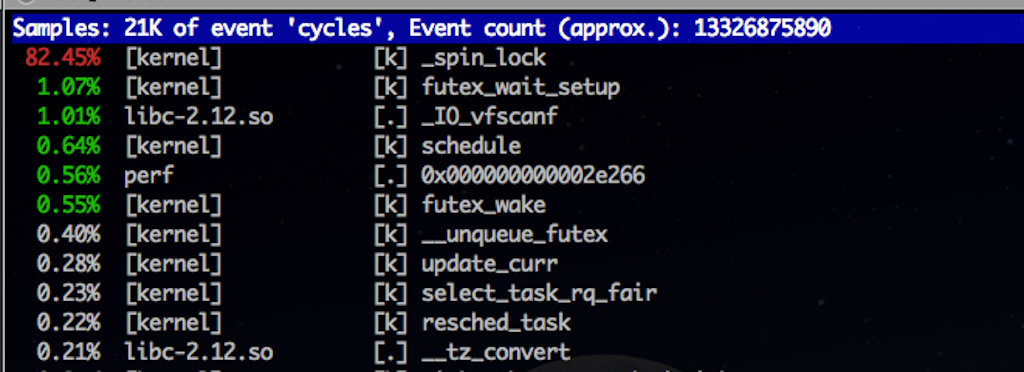
- perf top
通过perf top查看热点函数,可以看出_spin_lock是热点,CPU被内核的spin lock(自旋锁)占用。
- pstack
通过分析pstack获取到的MySQL进程的线程堆栈信息,可以发现和SQL执行相关的__lll_lock_wait_private()调用量比较大
|
|
为什么不是
poll(),select(),??()的问题呢?因为通过分析三个方法的调用栈,可以看出它们分别实现了读取网络包,读取DB数据以及异步IO相关的功能,和具体的SQL并无直接关系,所以可以排除这三个方法的嫌疑
通过分析__lll_lock_wait_private()的调用栈可以发现,在调用__tz_convert ()时会等待获取锁
|
|
- 修改time_zone,避免时区转换
修改time_zone为’+8:00’后再次压测,system cpu time显示正常。
自此可以确定是time_zone导致
解决方案
基本可行的两种解决方案
- 修改time_zone
最简单直接的解决方案,但是不适用于对时区敏感的业务系统
|
|
详细讲解MySQL Time Zone资料
- 使用DATETIME
或者统一使用DATETIME,而不使用TIMESTAMP,天生无时区转换问题,但是这种方案对现有系统的改造成本巨大
OS上关于DATETIME VS TIMESTAMP的讨论
触发条件
为什么之前未出现这类问题,这次突然出现了呢?经过DBA的压测,SQL的数据读取量在1K以下或者num_threads在10以下均不会出现,当然这个数据还需要结合MySQL服务器的硬件配置。所以和数据量以及MySQL当时处理有关,随着这张表的数据量的增长,就触发了这次故障。
