UPATE: 内容已更新到Elasticsearch v5.6
内存对Elasticsearch而言,非常重要,因为它为了提升性能使用了大量的in-memory数据结构。
官网推荐给Elasticsearch分配的内存不能超过32GB(小于32GB时会启用compressed oops,节省很多内存)
并且还必须是小于物理内存的50%,以便为Lucene利用Cached Memory提供更多的剩余内存。
Elasticsearch内部是如何使用这些内存的呢?下面这张图说明了Elasticsearch和Lucene对内存的使用情况。
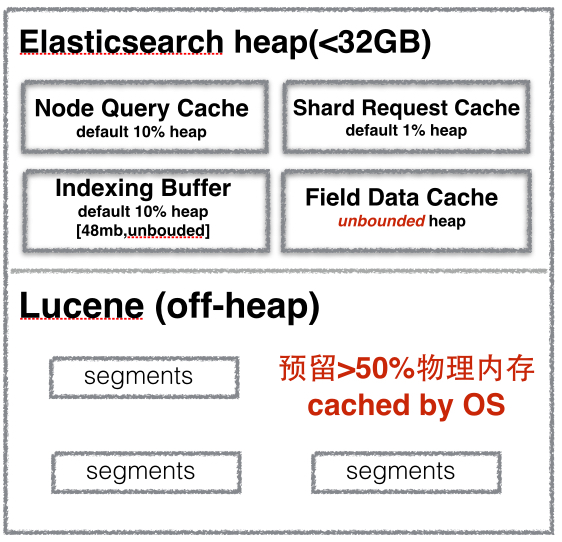
- Lucene对内存的使用
Elasticsearch是基于Lucene实现。Lucene的segments(包括用于全文检索的inverted index以及用于聚合的doc values)都存储在单个文件中,这些文件都是不可变的,被经常访问的segments会常驻在OS的内存中,从而提升Lucene的性能。
Lucene使用off heap,官方建议至少预留50%的物理内存给Luncene。
- Node Query Cache
每个节点都有一个Node Query Cache,被所有shards共享。它负责缓存使用了filter的query结果,因为filter query的结果要么是yes要么是no,不涉及到scores的计算,非常使用于Cache的场景。
集群中的每个data节点必须配置
默认10%,也可以设置为绝对值,比如512mb
|
|
- Indexing Buffer
用于存储最近被索引的文档,所有shards共享。当该buffer满了之后,buffer里面的文档会被写入一个segment。
|
|
- Shard Request Cache
只有reqeust size是0的才会被cache,比如aggregations、counts和suggestions。
不建议将它用于更新频繁的index,因为shard被更新时,该缓存会自动失效
|
|
- Field Data Cache
在analyzed字符串上对field进行聚合计算时,Elastisearch会加载该field的所有值到内存中,这些值缓存在Field Data Cache里面。
所以Fielddata是懒加载,并且是在query过程中生成的。
indices.fielddata.cache.size控制了分配给fielddata的heap大小。它的默认值是unbounded,这么设计的原因是fielddata不是临时性的cache,它能够极大地提升性能,而且构建fielddata又比较耗时的操作,所以需要一直cache。
如果没有足够的内存保存fielddata时,Elastisearch会不断地从磁盘加载数据到内存,并剔除掉旧的内存数据。剔除操作会造成严重的磁盘I/O,并且引发大量的GC,会严重影响Elastisearch的性能。
|
|
如果不在analyzed string fields上使用聚合,就不会产生Field Data Cache,也就不会使用大量的内存,所以可以考虑分配较小的heap给Elasticsearch。因为heap越小意味着Elasticsearch的GC会比较快,并且预留给Lucene的内存也会比较大。
-
查看内存使用情况
-
查看segments使用的内存
通过查看cat segments查看index的segments使用内存的情况1GET /_cat/segments?v -
查看Node Query Cache、Indexing Buffer和Field Data Cache使用的内存
通过cat nodes可以查看他们使用内存的情况1234GET /_cat/nodes?v&h=id,ip,port,v,master,name,heap.current,heap.percent,heap.max,ram.current,ram.percent,ram.max,fielddata.memory_size,fielddata.evictions,query_cache.memory_size,query_cache.evictions,request_cache.memory_size,request_cache.evictions,request_cache.hit_count,request_cache.miss_count
-
-
谨慎对待unbounded的内存
unbounded内存是不可控的,会占用大量的heap(Field Data Cache)或者off heap(segments),从而会导致Elasticsearch OOM
或者因segments占用大量内存导致swap。
segments和Field Data Cache都属于这类unbounded。-
segments
segments会长期占用内存,其初衷就是利用OS的cache提升性能。只有在Merge之后,才会释放掉标记为Delete的segments,释放部分内存。 -
Field Data Cache
默认情况下Fielddata会不断占用内存,直到它触发了fielddata circuit breaker。
fielddata circuit breaker会根据查询条件评估这次查询会使用多少内存,从而计算加载这部分内存之后,Field Data Cache所占用的内存是否会超过indices.breaker.fielddata.limit。如果超过这个值,就会触发fielddata circuit breaker,abort这次查询并且抛出异常,防止OOM。1indices.breaker.fielddata.limit:60% (默认heap的60%)如果设置了indices.fielddata.cache.size,当达到size时,cache会剔除旧的fielddata。
indices.breaker.fielddata.limit 必须大于 indices.fielddata.cache.size,否则只会触发fielddata circuit breaker,而不会剔除旧的fielddata。
-
